
| Full name: | CrossMedia Semantic Annotation and Search service |
| Start date: | 2010. 01. 05. |
| End date: | 2013. 01. 09. |
| Participants: |
|
As a result of the CrossMedia project, researchers of MTA SZTAKI created a new testbed to support media retrieval research activities. The platform consists of a portal providing domain-specific functionality, collaborative features and a multimodal user interface; and is supported by a robust and scalable backend system.
Researchers working in the field of media retrieval have always been in a tough situation as they need to deal with huge amounts of test data while evaluating the results of their scientific activities. Since processing visual and audible media requires large amounts of memory and computing power, there is an infrastuctural need to efficiently index, store, and retrieve information from multimedia databases. Sharing achievements or performing joint activities is a hard task in such a heavy-duty environment. Our new e-science platform supports collaborative research communities by providing a simple solution to develop semantic and media search algorithms on common datasets. The project was funded by MTA SZ TAKI – Hungarian Academy of Sciences, Institute for Computer Science and Control and was executed by the Department of Distributed Systems and the Distributed Events Analysis Research Laboratory.
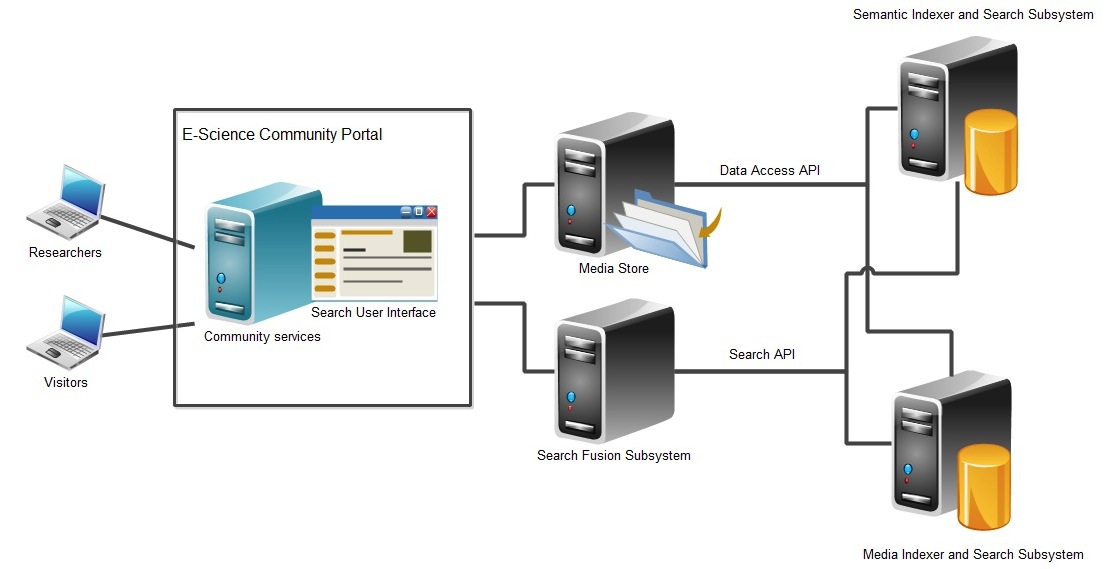
Fig. 1. Architecture of the CrossMedia e-science platform
Architecture of the platform is shown in Figure 1. The system’s functionality can be used through the portal served by a distributed backend system organized in a loosely coupled service-oriented architecture:
- The Media Store (MS) is responsible for safekeeping all searchable multimedia elements.
- The Media Indexer and Search Subsystem (MISS) is responsible for generating index trees for a specific algorithm on a specific media set in the MS and it is also capable of executing similarity-based search queries.
- The Semantic Indexer and Search Subsystem (SISS) is responsible for creating semantic databases and indices; and executing semantic search queries.
- The Search Fusion Subsystem (SFS) is responsible for combining the results of the MISS and SISS in case of multi-input multimodal search expressions.
- The Search User Interface (SUI) enables users to easily create complex multimodal search expressions and to evaluate results.
- The E-Science Community Portal (ECP) is responsible for integrating and providing all the functionality through a Web2.0 interface enabling users to perform collaborative research.
We separated the community management (ECP) and multimedia management (MS) functionality into loosely coupled components. This separation detaches storage functionality (millions of test data for the content based search) from the community portal’s permission control and keeps these management tasks independent; resulting in a flexible, scalable and responsive ecosystem overall.
Researchers can upload their media indexer algorithms through the portal. For evaluation, media collections can be created to build index trees for an algorithm. An image index is built using one indexer algorithm and one or more media collections. Defining an index on the portal interface launches a series of asynchronous automated operations, while the portal is regularly updated with status information (Figure 2.). Once ready, the generated index becomes available for testing via the user interface.
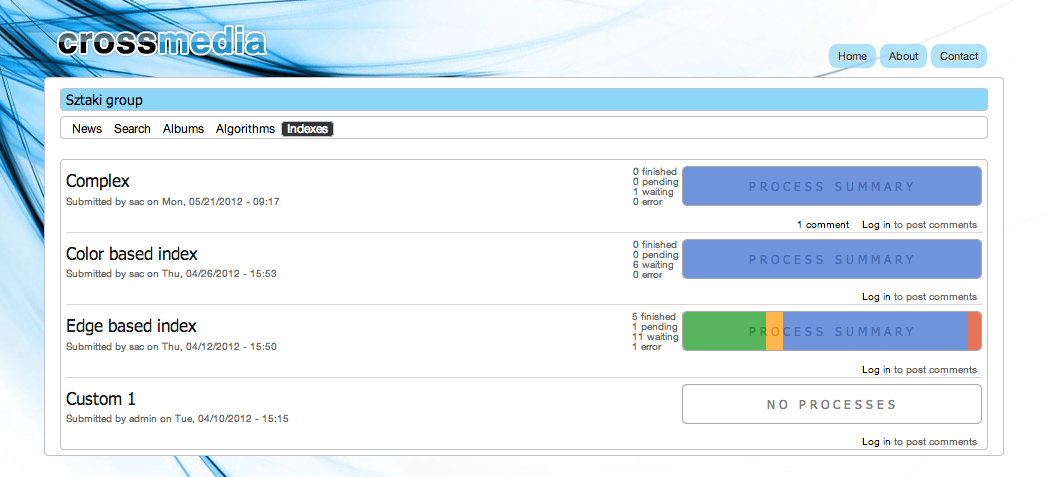
Fig. 2. Indices created by a research group shown on the portal
An index can either be content-based or annotation-based (semantic). Semantic and free text annotations can be attached to any media item, enabling the SISS to perform semantic search. The MISS overcomes the performance problems of content-based indices using a hybrid indexing structure (RAM-SSD-HDD combination) in a locally distributed computational framework. The applications are not limited to well-formed feature descriptors; indices can receive arbitrary binary data as a feature with the relating distance definition.
The applied LHI-tree is similar to M-index where base points are chosen randomly to reduce the high-complexity space. LHI-tree uses base points to compute reference distances and to calculate hash codes for every input vector from the quantized distances. To assign a disk partition to a part of the feature space, we used hashing function of quantized distances.
For the visual content indexing we built a descriptor composed of four different information representations: edge histogram, entropy histogram, pattern histogram, dominant color characteristics. The dimensionality of such descriptor is 52. We experimentally proved that a good choice for similarity measure is the weighted Euclidean distance where the fusion of the different features is carried out by tuning the weighting scalars.
Sample semantic indices were built for the CoPhiR database by matching photo metadata - such as tags and titles - to DBpedia nodes using entity extraction. Various semantic queries were then built, e.g. to find photos taken in a given time of day (sunset, morning), containing a given plant or animal, or taken at a given place. Our semantic reasoner exploits the transitivity of the semantic relations, therefore we find photos tagged with a narrower search term than the original one (e.g. trains -> Shinkansen).
Available functionality not only satisfies the domain-specific needs of an individual researcher but also offers community-based collaboration facilities as users can be engaged in research groups. Group members can work in the group’s private space and share content with other groups or with the public.
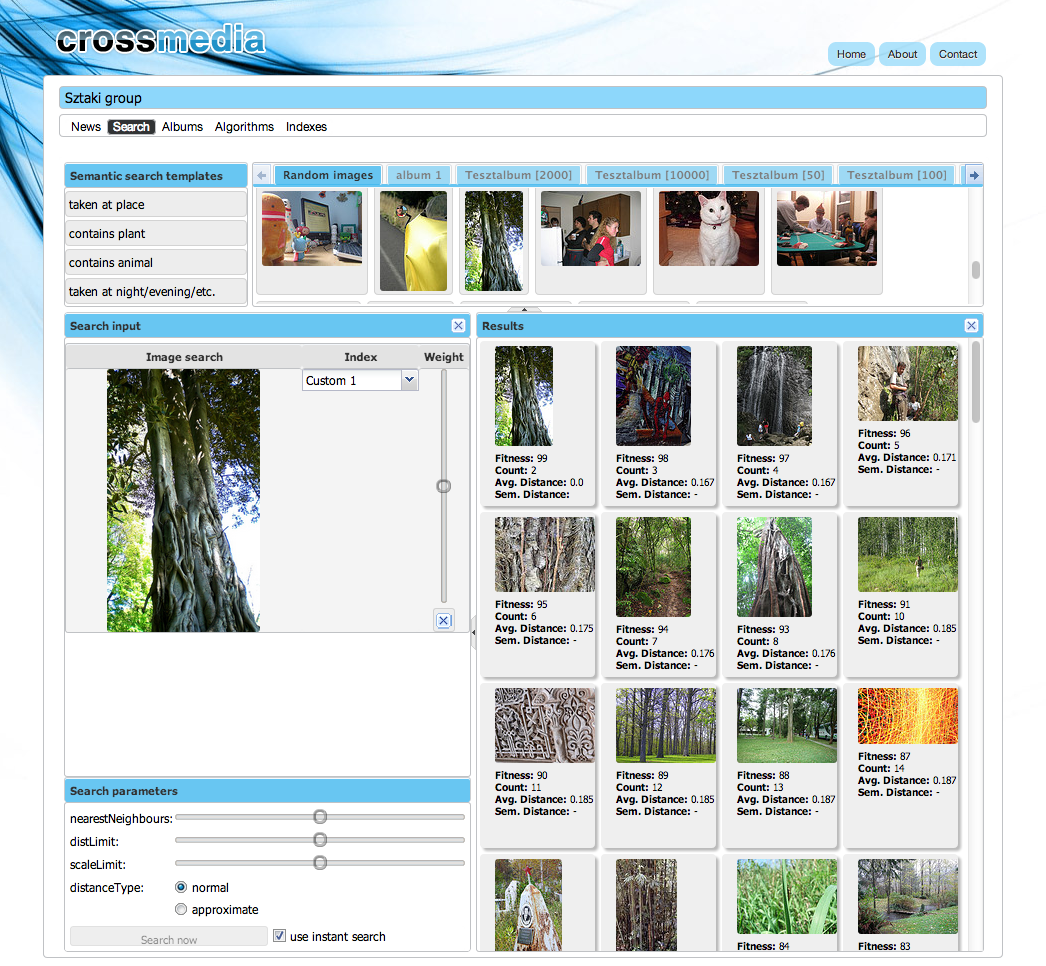
Fig. 3. Search user interface
The portal supports two ways for the fusion of the output of different indices: a general approach, where the lists are internally aggregated and re-ranked using the fitness value. The second option suits the non-compatible modalities (e.g. semantic-visual); in this case the visual search directly reduces the search space of the semantic search engine.
The search interface (shown in Figure 3.) allows testing image descriptors and semantic indices. Users can assemble complex multipart search queries, where each query consists of a media item and an index. Different indices may be combined in a multimodal query. Results for multipart queries are unified by the SFS using internal weighting mechanisms, which can be fine-tuned by the user moving an item forward or backward in the result list.
Using the CrossMedia e-Science Community Portal researchers gain the possibility to work in groups and to collaborate with other research communities. The infrastructure ensures scalable and fast manipulation of indices, while the user interface provides testing and evaluation facilities. As to be able to meet a growing need to use the portal’s potentials, we plan to adopt the SZTAKI Cloud infrastructure to ensure maximum processing speed and availability.