
| Full name: | Metadata Architecture for Rating, Filtering & Recommender Services |
| Number: | TAP RE 4008 |
| Start date: | 1998. |
| End date: | 2000. |
| Participants: |
|
| Project homepage: | http://dsd.sztaki.hu/projects/past/select/en/ |
Short abstract
Internet started as a network for science and technology, and still a large part of the documents available on the Internet are scientific and technical documents provided by universities and other research and educational organisations. However, the spread of availability of the Internet to commercial organisations and to undergraduate students has meant a decline in the reliability of the documents available on the net. Nowadays, when you use the web to look up a document, or read a message in e-mail or Usenet News, you cannot trust the correctness of the document. This has reduced the usefulness of the network for use by scientific and technical professionals.
In normal scientific and technical communication, a number of instruments are available to safeguard the quality of the information. Examples of this are peer-reviewed journals and conferences and the academic traditions of thesis development and presentation. Other EU-funded projects have tried to remedy this problem by copying the traditional methods onto networked applications, for example by peer-reviewed electronic journals. The disadvantage with this method is that it is expensive, time-consuming, and in practice only provide quality for a small number of networked documents.
This project aims at helping to solve this problem in another way. We have developed rating and intelligent filtering tools, which help users find the information of value. Filtering for one scientific and technical user is based on ratings provided by other users with similar competence and on other filtering criteria. Rating and filtering is provided on documents in mailing lists, in Usenet News, in other mesaging services like TAP Web4Groups and on Web documents. We have as partners in this project two of the most successful European providers of Internet search services, EuroSeek and Arianna, and they provide our rating and filtering services to their users.
Users involved were two major European providers of Internet search services, who use the results to improve their services, and their customer groups. Users were also two specialised Internet user groups of scientific and technical people.
Techonology approach: Data bases of ratings of documents on the net, filters using these data bases based on a knowledge data base of the interests, values and competence of users and rating providers, methods to improve this data base with or without explicit user interaction.
Summary
The objectives of this project was to help Scientific, Technical and other professional Internet users to get and find the most reliable, valuable, important and interesting information and to avoid trash and reduce information overload. The service we have developed is available to users of World Wide Web, Usenet News, e-mail mailing lists, and non-simultaneous computer conferencing system like Web4Groups. We were not only directed at users who search for specific information on the net, but also on users who use the net to keep up to date with what is happening in particular areas.
The methods to achieve these objectives was to develop, demonstrate and user test rating and intelligent and non-intelligent filtering tools. By rating tools we mean tools for users to evaluate and store their ratings (gradings, quality assessments) of Internet documents and resources. By filtering we mean tools to automatically scan Internet documents and resources before delivery to the users. The result of filtering can be an ordering of documents and resources with the most interesting first, marking up of documents and resources with codes to help the user in manual decisions on what to read and can also in some cases mean that less interesting items are discarded and not shown to a user. Which of these results is used depends on the user needs: For important areas to a particular user, the filter should sort items, not discard them, but for less important areas, the user may prefer that the filter automatically discards items. Filtering can also be based on ratings provided by the author of an item or by other readers of that item. In particular, we have developed tools to select items based on ratings made by people with similar values, competence and interests as the person for whom the filtering is done.
The filters appear to the users as additions or plug-ins to their ordinary reading and browsing tools, but in reality part of the filtering process are done in servers, since downloading everything to the personal computer of a user before filtering can be time-consuming and inefficient.
Part of this project is to develop and test different filtering methods (methods of assigning attributes to documents, methods of using these attributes to filter messages, methods of finding the suitable filtering rules for each user). We tested both automatic methods, where the computer derives the filtering conditions from user actions or evaluations of documents, and manual methods, where interaction between the user and the filter is used to establish the filtering conditions. One type of filtering which we have developed is intelligent filtering. By this is meant that the computer uses machine learning techniques to derive a knowledge data base of information about the preferences of a user to use in filtering for that user. We have also developed filtering which uses interaction with the user to develop this data base. This interaction with the user need not mean that the user has to specify complete Boolean expressions, they can be based on other kinds of interactions, for example that the computer questions the user only for items which the user rated differently than the filter algorithm expected.
We have in this project partners who are service providers of Internet search services. These partners enhance their search services with data bases of rating information. These data bases are used, when users so wish, to enhance the search service. The data bases are accessible for rating and filtering of newsgroup postings, e-mail mailing list messages and messages in conferencing systems like TAP Web4Groups. Their customers are the users on which we tested and demonstrate the software we have developed, but our project also included user organisations representing different Internet user groups.
Integration to AQUA
AQUA is a management system for scientific documents, which has been developed by SZTAKI in another EU funded project. SELECT enhances that service with the input of rates, possibly on 2-3 categories with a separate dialog box from the document preview panel.
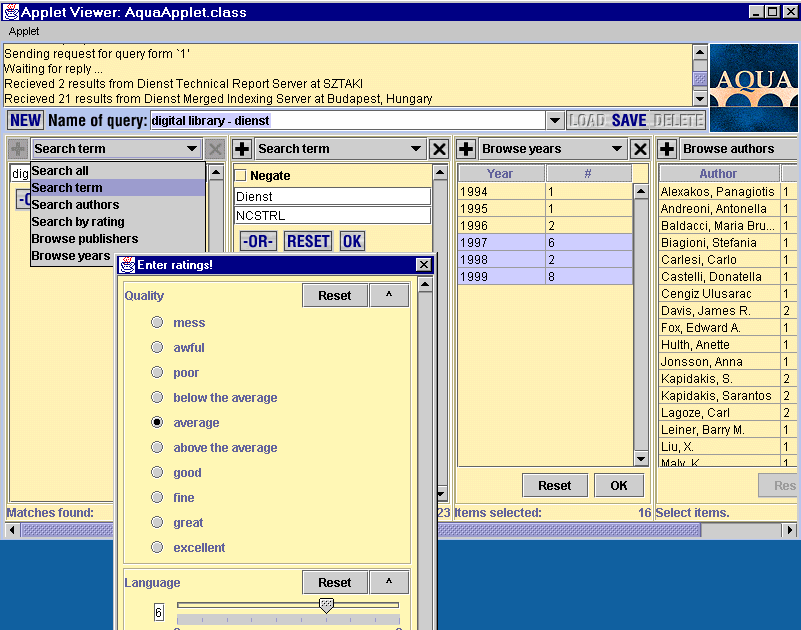
The following SELECT related functions are available:
- Show rates for documents in the document preview panel. (Includes: overall rate, number of raters and user's rate for all categories)
- Show overall rates in the document list (in a selected category).
- Search for documents which have their overall rate in a given interval.
All these functionalities communicate with a remote SELECT server to store/retrieve rates.
Users can express their opinion on technical reports. Also, overall rating values help them while browsing large sets of scientific documents.