

| Teljes név: | CrossMedia Szemantikus Annotációs és Kereső szolgáltatás |
| Kezdet: | 2010. 05. 01. |
| Lezárás: | 2013. 09. 01. |
| Résztvevők: |
|
Az új keresési megoldások kifejlesztése sok kísérletezést igényel, és az ezzel kapcsolatos tevékenységet kívánjuk egy e-science közösségi platformmal támogatni. A létrehozott megoldás keretet ad többféle keresési algoritmus egyidejű kipróbálására, kombinálására, valamint a tesztadatok megosztására. A platform részeként újfajta képkereső és szemantikus kereső is megvalósult.
E-science platformunk célja a képi és a szemantikus keresőalgoritmusok iteratív fejlesztési folyamatának támogatása, a kutatói csoportok kollaboratív működésének segítése. A CrossMedia rendszerben lehetőség nyílik a keresések fejlesztésére felhasznált adathalmazok kollaboratív építésére, bővítésére, azok különböző szinteken történő megosztására.
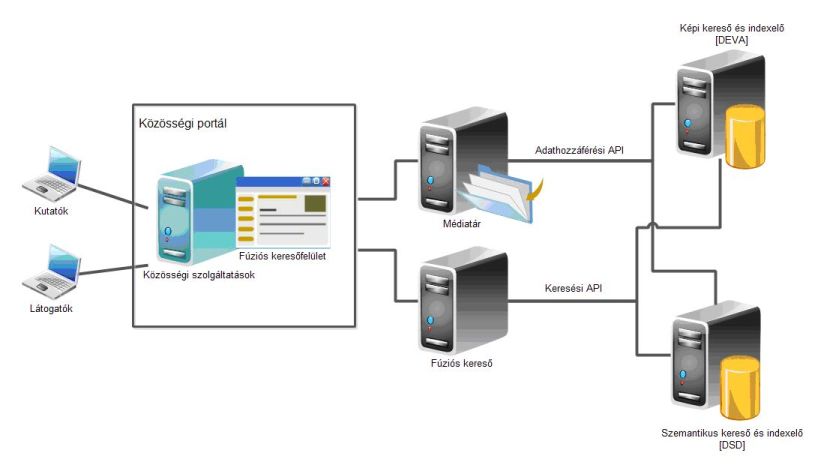
A kifejlesztett képleíró és szemantikus keresési indexek tesztelésére egy jól áttekinthető, könnyen és intuitívan kezelhető keresőfelületet hoztunk létre. A felület biztosítja az elérhető média-adatbázison az indexekre vonatkozó összetett keresési feltételek megfogalmazását és az összefésült találati eredmények megjelenítését. A keresőfelületet böngésző- és platformfüggetlen web-alkalmazásként implementáltuk, működése teljes mértékben Ajax technológiára épül. Az indexek és a kollekciók külvilág felé is megoszthatók, melynek révén az eljárások külső látogatók számára is elérhetővé válnak. Így a portál demonstrációs felületként is szolgálhat a kutatói csoportok számára, illetve a publikációs tevékenységet is támogatja.
Demonstrációs célokra a keretrendszerbe töltöttünk körülbelül 5 millió képet és metaadatait, továbbá a képekről kinyert MPEG-7 leírókat. A szemantikus index építéséhez a DBpedia által szolgáltatott RDF adatokat társítottuk a képek metaadataihoz entity extraction módszerek alkalmazásával. Ezután célzott szemantikus kereséseket valósítottunk meg, mint például napszak vagy helyszín szerinti keresés.
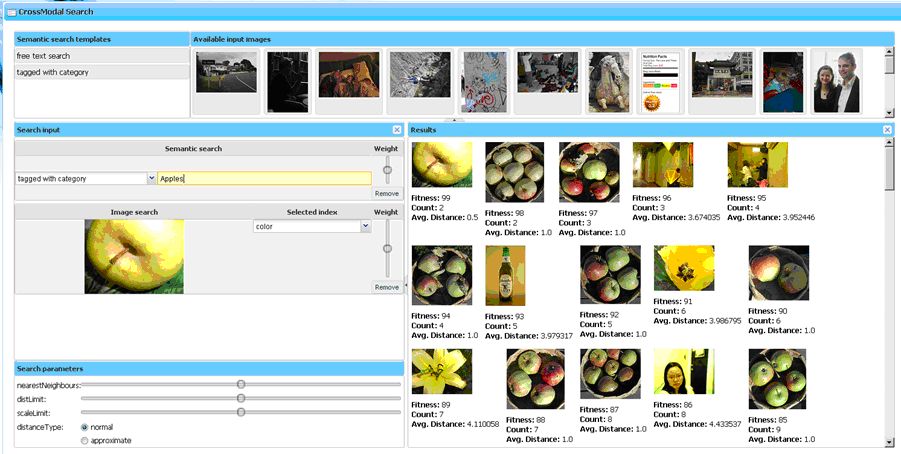
Képtartalom alapú kereséshez MPEG-7 képleírókat alkalmaztunk, melyek közül a color-structure, edge histogram és homogenous texture leírók bizonyultak a leginkább alkalmasnak a képtartalom szerinti illeszkedés keresésére. A nagy mennyiségű és nagy dimenziószámú adatok kereshetővé tétele speciális adatstruktúrát igényel. A megoldásunk fő szempontja volt, hogy változó dimenzió-számú leírók és nem metrikus távolság definíciók is alkalmazhatók legyenek. A kellő gyorsaság biztosításához a memória és a különböző sebességű háttértárak kombinált alkalmazására optimalizáltuk a kereső algoritmust. Ily módon az ismert memória-alapú képkeresőkhöz hasonló sebességű, de lemez-alapú indexkezelési algoritmusokat hoztunk létre, ezzel lehetővé téve a nagyméretű képadatbázisok használatát.