
| Teljes név: | Szociológiai Szövegelemző (az MI Nemzeti Laboratórium alprojektje) |
| Kezdet: | 2021. 03. 01. |
| Lezárás: | 2022. 03. 01. |
| Résztvevők: |
|
| A projekt honlapja: | https://mi.nemzetilabor.hu/ |
| Vezető: | Micsik András |
A Társadalomtudományi Kutatóközpont Kutatási Dokumentációs Központjának két archívuma, a KDK, amely a TK intézeteiben zajló kutatásokat archiválja, és a 20. Század Hangja Archívum és Kutatóműhely, amely a hazai kvalitatív társadalomkutatások örökségét őrzi, pilot projektben vett részt a SZTAKI-val együttműködésben. A projekt célja a két archívum interjúgyűjteményének tárgyszavakkal és egyéb metaadatokkal való ellátása volt (pl. nevek és helyek felismerése) mesterséges intelligencia eszközök felhasználásával.
A munka újszerűsége és fő kihívása egyfelől az, hogy nem jól kategorizálható kutatási produktumokhoz (pl. tudományos publikációkhoz), hanem sokkal nehezebben kategorizálható kutatási háttéranyagokhoz (interjúkhoz) társít leíró adatokat, másfelől az, hogy olyan gépi módszereket alkalmaz, amelyek ezen a speciális területen még gyerekcipőben járnak, illetve amelyek nem néhány, hanem néhány száz kategóriával kell, hogy dolgozzanak.
A projekt célja, hogy javítsa a két archívum weboldalán az interjús anyagok kereshetőségét, valamint segítse az archívumok által őrzött anyagok kutathatóságát.
A megvalósítás során a KDK-tól kapott 368 interjút feldolgoztuk saját fejlesztésű scriptekkel, amelyek a bejövő PDF, RTF, MS Word, TXT formátumokból kinyerték a metaadatokat, beszámozták a bekezdéseket, végül TXT és TEI XML kimenetet állítottak elő.
Tárgyszókészletnek a European Language Social Science Thesaurus-t (ELSST) vettük alapul, amelynek magyarra fordítását automatikus fordítással segítettük.
Az előfeldolgozott szövegekből kiválasztott 20 interjút szakértők tárgyszavazták Label Studio segítségével. Az így előállított gold standard segítségével kipróbáltunk számos tárgyszavazó módszert, illetve egy saját módszert is kifejlesztettünk. A gyengébben teljesített módszerek (pl. MLLM, STWFSA) az alábbi grafikonon nem szerepelnek:
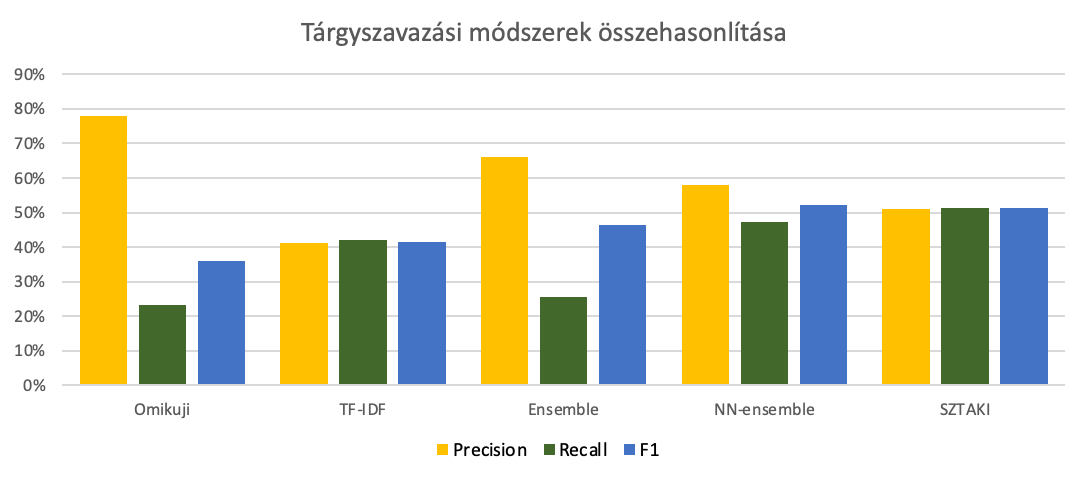
Az interjúszövegek részletes elemzéséhez összegyűjtöttük és kipróbáltuk a főbb Pythonnal integrálható magyar NLP technológiákat, például: szótövezés (NLTK, Spacy, emtsv), kulcsszavazás (keybert, textacy, stb.), dátumfelismerés (datefinder, dateparser), névelem-felismerés (Spacy, emtsv, Wikifier). Saját névelem-felismerőt készítettünk a Hubert modell továbbtanításával a NER-KOR korpuszon, és ez teljesített a legjobban névelem-felismerésben. Végül kigyűjtöttük a felismert tulajdonnevekre vonatkozó linkeket a fontosabb nyilvántartásokból, tudásbázisokból mint például Wikidata, VIAF, Geonames.
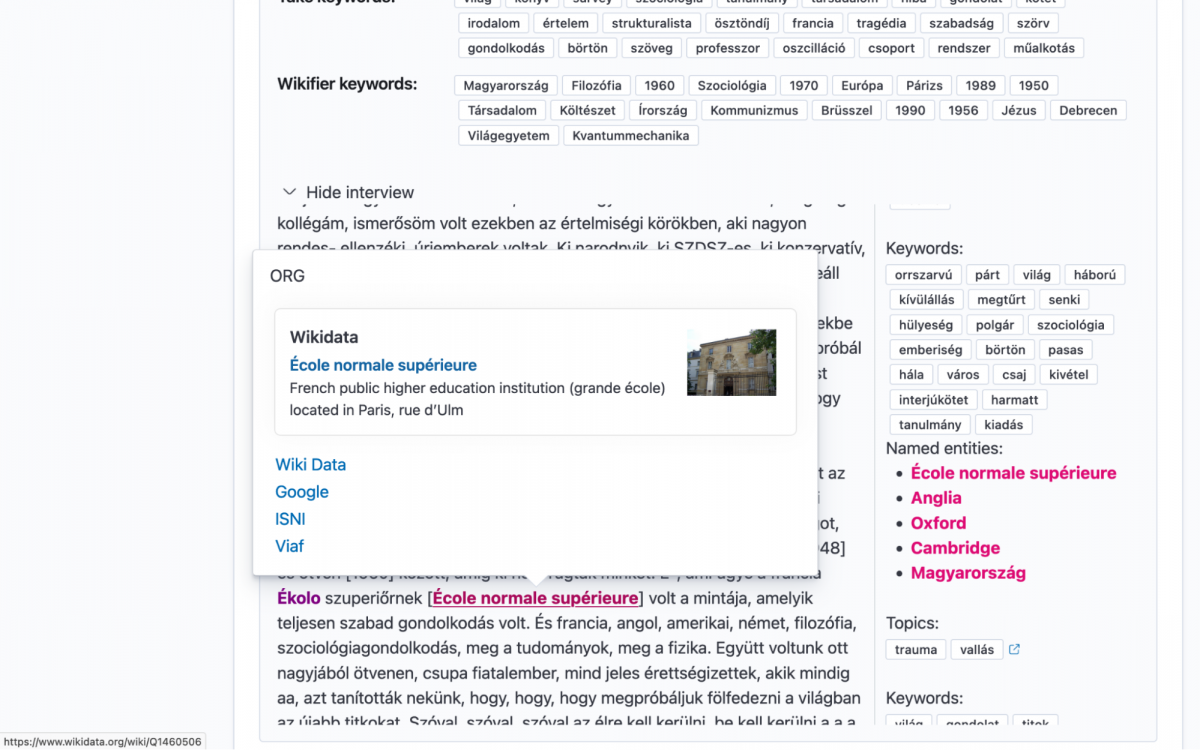
A feldolgozott szövegeket egy fazettás keresőben tettük elérhetővé, amely a szöveg olvasása közben megjeleníti a géppel hozzárendelt kulcsszavakat és tárgyszavakat, valamint a névelemekhez kapcsolódó plusz információt is egy felugró ablakban:
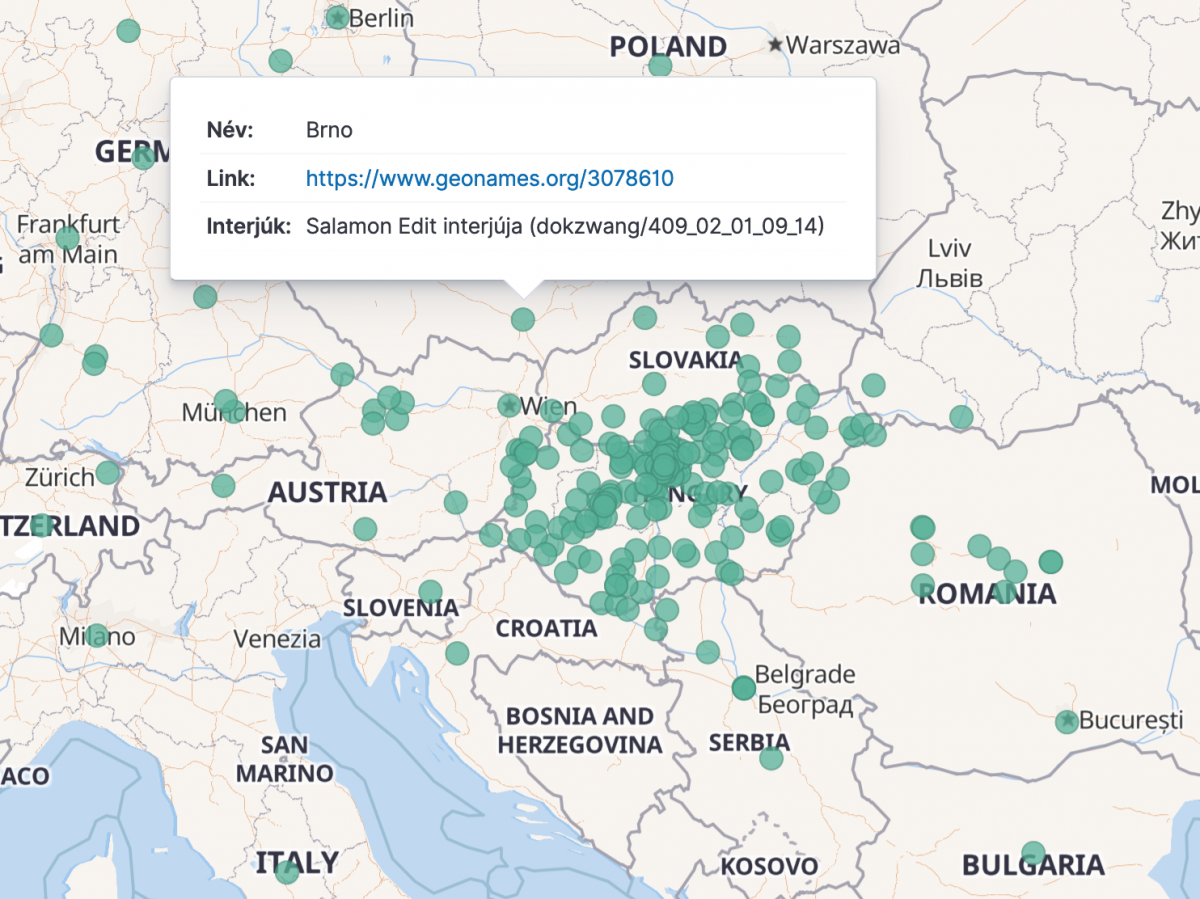
A kereső indexelése alapján sokféle grafikonos és térképes vizualizáció is készíthető, akár a kutató felhasználók által is:
Előadások a projekt eredményeiről:
-
TK MILAB Speaker Series 2021-07-17 https://milab.tk.hu/esemeny/2021/05/gardos-judit-eloadasa-a-tk-milab-speaker-series-sorozat-kovetkezo-allomasakent
-
TK MILAB Speaker Series 2022-03-31
-
https://milab.tk.hu/esemeny/2022/02/gardos-judit-es-micsik-andras-eloadasa-tk-milab-speaker-series
-
Networkshop 2022-04-20 https://networkshop.cloud.panopto.eu/Panopto/Pages/Viewer.aspx?id=f3d7eb0e-6ed2-4ed8-9992-ae7d00c4bae7