
| Full name: | Sociology Text Explorer (subproject of AI National Laboratory) |
| Start date: | 2021. 03. 01. |
| End date: | 2022. 03. 01. |
| Participants: | |
| Project homepage: | https://mi.nemzetilabor.hu/ |
| Coordinator: | András Micsik |
The Research Documentation Centre (KDK) of the Centre for Social Sciences runs two archives of social science research, which preserve the primary research data for qualitative social science in Hungary. A need emerged to annotate and enrich interviews collected in these archives with assigned keywords, topics and recognised named entities (places, persons and organisations). KDK and SZTAKI launched a pilot project on using NLP and AI for automated text enrichment.
The difficulties of this pilot lay first in the specialities of interview transcripts and secondly in the maturity of NLP tools for processing transcripts of informal Hungarian speech.
The project aimed at improving the visibility of these interviews and to support researchers in the re-use of old research data.
First, we processed 368 selected interviews with custom scripts, extracted metadata from the original PDF, RTF, MS Word files, converted them to TEI XML and TXT and numbered text paragraphs to be used for identification.
We used the European Language Social Science Thesaurus (ELSST) as a starting point to translate and customize our own topic hierarchy.
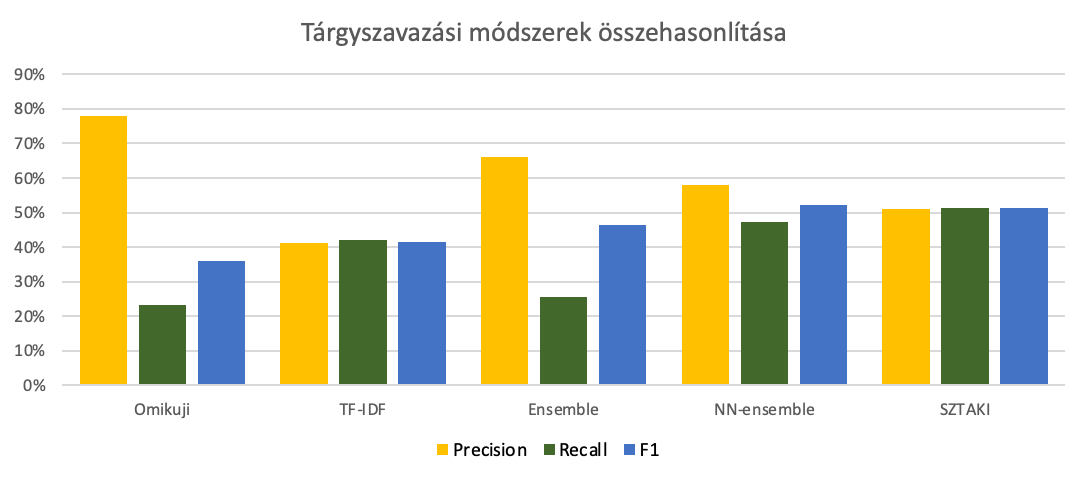
A gold standard for topic assignment was established by experts using Label Studio software. Several algorithms for extreme classification were trained and evaluated based on the gold standard, and we also developed our own classification method. The figure below shows the performance of the better methods:
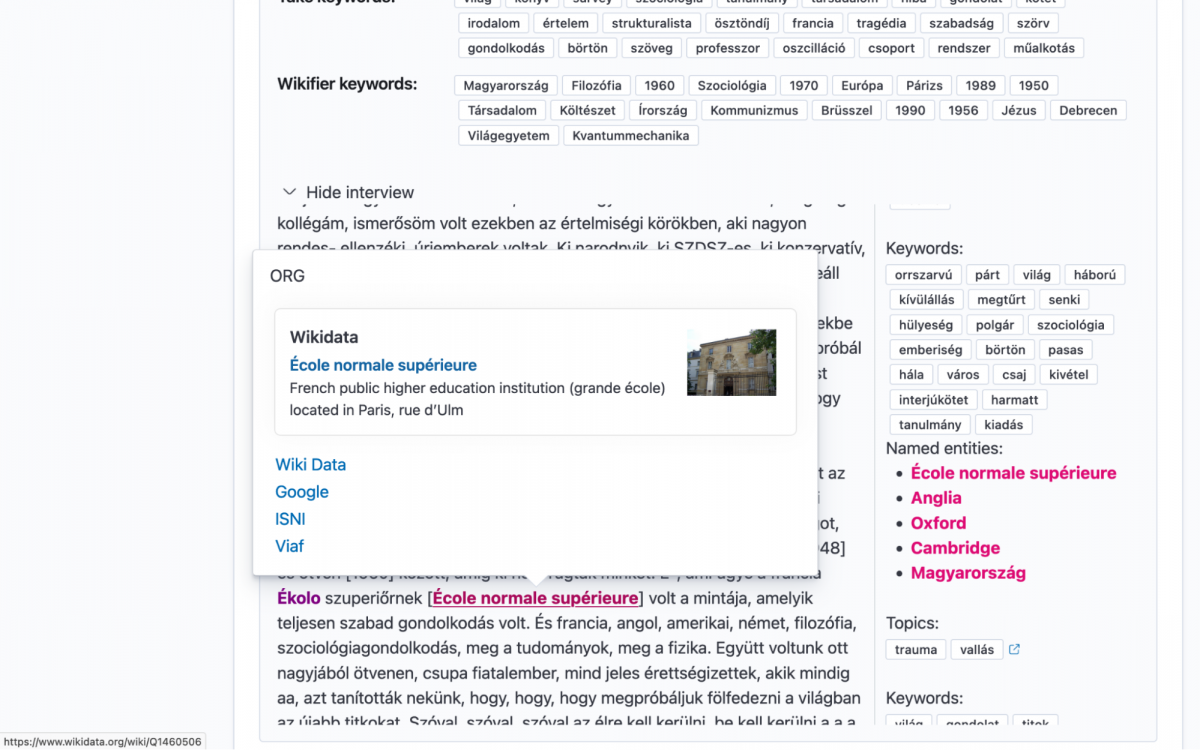
For detailed processing of interview texts we collected, tried and compared major Python-based NLP tools. For example NLTK, huspacy and emtsv for stemming, keybert and textacy (both supporting 4+ algorithms) for keyword extraction, datefinder and dateparser for date recognition, huspacy, emtsv and Wikifier for named entity recognition (NER). We trained our own model for NER on the NER-KOR corpus based on Hubert, which had the best performance in NER. Finally, named entity linking was performed for major registries and knowledge graphs such as Wikidata, VIAF and Geonames.
Processed texts were made available in a faceted search interface, which presents machine-assigned keywords, topics along with the text, and presents extra information on named entities in a popup window.
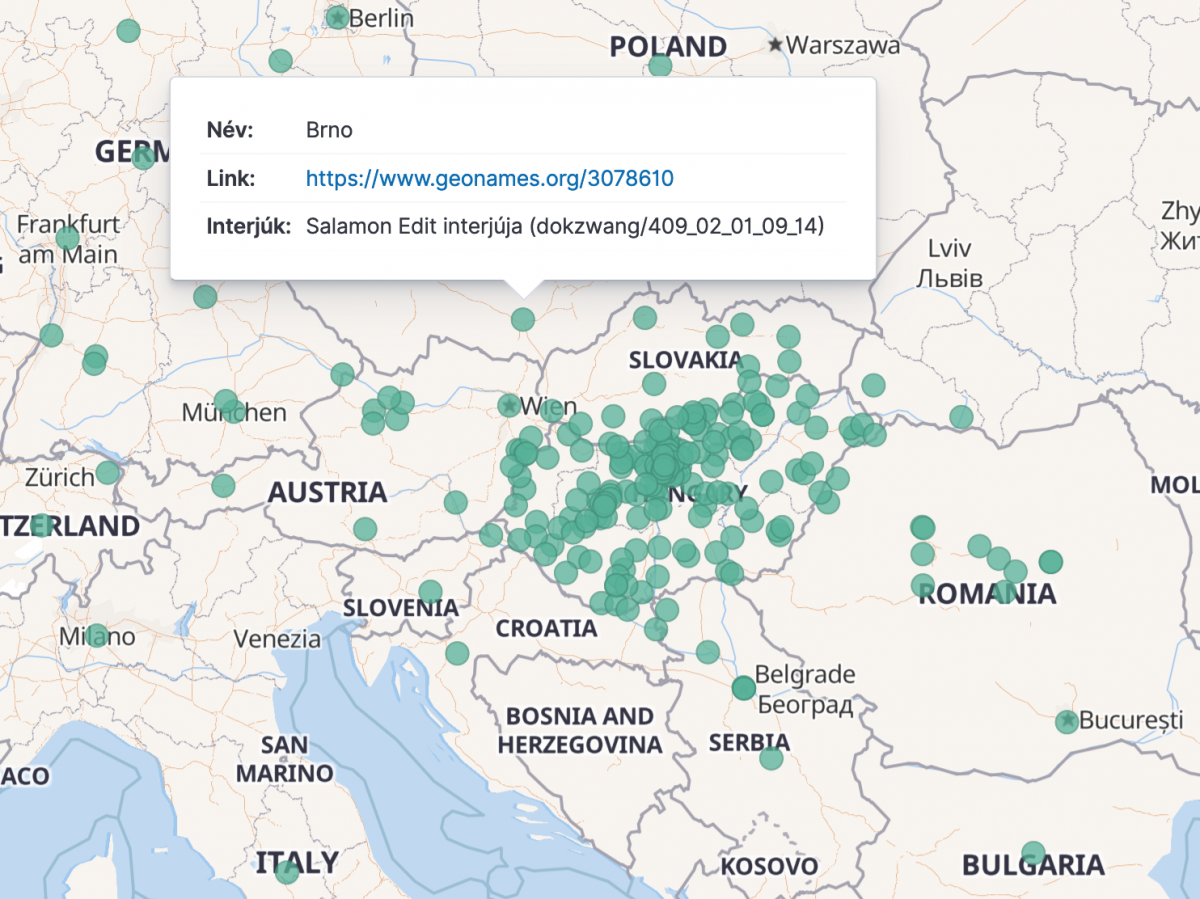
The indexes of the search interface enable the creation of various diagrams and mashups even by the researchers using the interface:
Presentations about the project:
-
TK MILAB Speaker Series 2021-07-17 https://milab.tk.hu/esemeny/2021/05/gardos-judit-eloadasa-a-tk-milab-speaker-series-sorozat-kovetkezo-allomasakent
-
TK MILAB Speaker Series 2022-03-31
-
https://milab.tk.hu/esemeny/2022/02/gardos-judit-es-micsik-andras-eloadasa-tk-milab-speaker-series
-
Networkshop 2022-04-20 https://networkshop.cloud.panopto.eu/Panopto/Pages/Viewer.aspx?id=f3d7eb0e-6ed2-4ed8-9992-ae7d00c4bae7